初入坑Python,打算跟着沫凡小哥的学习视频打个基础,此篇文章做一些简单的学习记录,加油加油加油啦
沫凡小哥的学习网站:https://morvanzhou.github.io/tutorials/python-basic/basic/
安装
1.1 安装
Python下载网站:https://www.python.org/downloads/(注意环境变量的配置)
基本使用
2.1 print功能
与之前所学习的语言等的功能类似
补充一下print的注意点

另外,print('I love food'*5)是输出五次的I love food,如果把*改为+则报错,因为+号两边的数据类型应是一致的。
敲完满屏的print后,百度了一下IDLE的清屏指令,贴出找到的清屏方法供参考:
(1)ctrl+F6是restart
(2)下载或右击另存为,保存在Python X\Lib\idlelib目录下,并找到config-extensions.def以记事本打开,在最后加上
ClearWindow]enable=1enable_editor=0enable_shell=1[ClearWindow_cfgBindings]clear-window=
2.2 基础数学运算
基本的加减乘除、取余取整运算等,注意与matlab中幂^的不同,python中的幂为**
2.3 变量variable
while和for循环
3.1 while循环
基本使用(注意冒号):
while condition: expressions
python中除了常规比较操作会返回True和False值,其他也会返回True和False
(1)数字
数字和浮点数也能进行Boolean操作,若该值等于0或0.0返回False
(2)None类型
若while后面跟的语句类型为None,返回False
(3)集合类型
python中集合类型有list、tuple、dict和set等,若把该集合对象作为while判断语句,如果集合中的元素数量为0,那么将会返回False
3.2 for循环
基本使用:
for item in sequence: expressions
sequence为可迭代的对象,item为序列中的每个对象。
range使用
在Python内置了工厂函数,range 函数将会返回一个序列,总共有三种使用方法
1.range(start, stop)
其中 start 将会是序列的起始值,stop为结束值,但是不包括该值,类似数学中的表达 [start, stop),左边为闭区间,右边为开区间。
2.range(stop)
如果省略了 start 那么将从 0 开始,相当于 range(0, stop)
3.range(start, stop, step)
step 代表的为步长,即相隔的两个值得差值。从 start 开始,依次增加 step 的值,直至等于或者大于 stop
关于此节课程下的高级主题
4.1 内置集合
Python共内置了 list、 tuple 、dict 和 set四种基本集合,每个集合对象都能够迭代。
tuple 类型
tup=('python',2.7,64)
for i in tup:
print(i)
程序将以此按行输出 ‘python’, 2.7 和 64。
dictionary 类型
dic={}
dic['lan']='python'
dic['version']=2.7
for key in dic:
print(key,dic[key])
字典在迭代的过程中将 key作为可迭代的对象返回。注意字典中key是乱序的,也就是说和插入的顺序是不一致的。如果想要使用顺序一致的字典,请使用collections模块中的OrderedDict对象。
set 类型
s=set(['python','python2','python3','python'])
for i in s:
print(i)
set 集合将会去除重复项,注意输出的 结果也不是按照输入的顺序。
4.2 迭代器
python 中的 for 句法实际上实现了设计模式中的 ,所以我们自己也可以按照迭代器的要求自己生成迭代器对象,以便在 for 语句中使用。 只要类中实现了 __iter__ 和 next函数,那么对象就可以在 for 语句中使用。现在创建 Fibonacci 迭代器对象,
4.3 生成器
除了使用迭代器以外,Python 使用 yield 关键字也能实现类似迭代的效果,yield 语句每次执行时,立即返回结果给上层调用者,而当前的状态仍然保留,以便迭代器下一次循环调用。这样做的好处是在于节约硬件资源,在需要的时候才会执行,并且每次只执行一次。
if判断
4.1 if判断
基本使用:
if condition: expressions
注意python中赋值语句同matlab,使用==表示。
4.2 if else判断
基本使用:
if condition: true_expressionselse: false_expressions
注意python中无类似condition ? value1 : value2 的三目操作符,但可以通过if-else来完成类似功能。var = var1 if condition else var2
4.3 if elif else判断
if condition1: true1_expressionselif condition2: true2_expressionselif condtion3: true3_expressionselif ... ...else: else_expressions
定义功能
5.1 def函数
基本使用:
def function_name(parameters): expressions
Python 使用 def 开始函数定义,紧接着是函数名,括号内部为函数的参数,内部为函数的具体功能实现代码,如果想要函数有返回值, 在 expressions 中的逻辑代码中用 return 返回。
5.2 函数参数
基本使用:
def function_name(parameters): expressions
注意:在调用函数时候,参数个数和位置一定要按照函数定义。如果我们忘记了函数的参数的位置,只知道各个参数的名字,可以在 函数调用的过程中给指明特定的参数 func(a=1, b=2), 这样的话,参数的位置将不受影响,所以 func(b=2,a=1)是同样的效果。
5.3 函数默认参数
定义函数时有时候有些参数在大部分情况下是相同的,只不过为了提高函数的适用性,提供了一些备选的参数, 为了方便函数调用,可将这些参数设置为默认参数,那么该参数在函数调用过程中可以不需要明确给出。
def function_name(para_1,...,para_n=defau_n,..., para_m=defau_m): expressions
函数声明只需要在需要默认参数的地方用 = 号给定即可, 但是要注意所有的默认参数都不能出现在非默认参数的前面。
此节课程下的进阶篇
3.1 自调用
如果想要在执行脚本的时候执行一些代码,比如,可以在脚本最后加上单元测试代码,但是该脚本作为一个模块对外提供功能的时候单元测试代码也会执行,这些往往我们不想要的,我们可以把这些代码放入脚本最后:
if __name__ == '__main__': #code_here
如果执行该脚本的时候,该if判断语句将会是True,那么内部的代码将会执行。 如果外部调用该脚本,if判断语句则为False,内部代码将不会执行。
3.2 可变参数
顾名思义,函数的可变参数是传入的参数可以变化的,1个,2个到任意个。当然可以将这些参数封装成一个 list 或者 tuple 传入,但不够 pythonic。使用边长参数可以很好解决该问题,注意可变参数在函数定义不能出现在特定参数和默认参数前面,因为可变参数会吞噬掉这些参数。
def report(name, *grades): total_grade = 0 for grade in grades: total_grade += grade print(name, 'total grade is ', total_grade)
定义了一个函数,传入一个参数为 name, 后面的参数 *grades 使用了 * 修饰,表明该参数是一个可变参数,这是一个可迭代的对象。该函数输入姓名和各科的成绩,输出姓名和总共成绩。所以可以这样调用函数 report('Mike', 8, 9),输出的结果为 Mike total grade is 17, 也可以这样调用 report('Mike', 8, 9, 10),输出的结果为 Mike total grade is 27
3.3 关键字参数
关键字参数可以传入0个或者任意个含参数名的参数,这些参数名在函数定义中并没有出现,这些参数在函数内部自动封装成一个字典(dict).
def portrait(name, **kw): print('name is', name) for k,v in kw.items(): print(k, v) 定义了一个函数,传入一个参数 name, 和关键字参数 kw,使用了 ** 修饰。表明该参数是关键字参数,通常来讲关键字参数是放在函数参数列表的最后。如果调用参数 portrait('Mike', age=24, country='China', education='bachelor') 输出:
name is Mike
age 24country Chinaeducation bachelor通过可变参数和关键字参数,任何函数都可以用 universal_func(*args, **kw) 表达。
变量形式
6.1 全局&局部 变量
模块安装
7.1 模块安装



文件读取
8.1 读写文件1
text='This is my first test.\nThis is next line.\nThis is last line.'my_file=open('my file.txt','w')my_file.write(text)my_file.close() 8.2 读写文件2
append_text='\nThis is appended file.' # 为这行文字提前空行 "\n" my_file=open('my file.txt','a') # 'a'=append 以增加内容的形式打开 my_file.write(append_text) my_file.close() 8.3 读写文件3

class类
9.1 class 类
class Calculator: #首字母要大写,冒号不能缺 name='Good Calculator' #该行为class的属性 price=18 def add(self,x,y): print(self.name) result = x + y print(result) def minus(self,x,y): result=x-y print(result) def times(self,x,y): print(x*y) def divide(self,x,y): print(x/y)"""">>> cal=Calculator() #注意这里运行class的时候要加"()",否则调用下面函数的时候会出现错误,导致无法调用.>>> cal.name'Good Calculator'>>> cal.price18>>> cal.add(10,20)Good Calculator30>>> cal.minus(10,20)-10>>> cal.times(10,20)200>>> cal.divide(10,20)0.5>>>""""
9.2 class 类 init 功能
class Calculator: name='good calculator' price=18 def __init__(self,name,price,height,width,weight): # 注意,这里的下划线是双下划线 self.name=name self.price=price self.h=height self.wi=width self.we=weight"""">>> c=Calculator('bad calculator',18,17,16,15)>>> c.name'bad calculator'>>> c.price18>>> c.h17>>> c.wi16>>> c.we15>>>"""" input输入
10.1 input 输入
11.1 元组 列表
a_tuple = (12, 3, 5, 15 , 6)another_tuple = 12, 3, 5, 15 , 6a_list = [12, 3, 67, 7, 82]
11.2 list 列表
a = [1,2,3,4,1,1,-1]a.append(0) # 在a的最后面追加一个0a.insert(1,0) # 在位置1处添加0a.remove(2) # 删除列表中第一个出现的值为2的项print(a[0]) # 显示列表a的第0位的值print(a[-1]) # 显示列表a的最末位的值print(a[-3:]) # 显示列表a的倒数第3位及以后的所有项的值print(a[0:3]) # 显示列表a的从第0位 到 第2位(第3位之前) 的所有项的值print(a.index(2)) # 显示列表a中第一次出现的值为2的项的索引print(a.count(-1))# 统计列表中某值出现的次数a.sort() # 默认从小到大排序a.sort(reverse=True) # 从大到小排序
11.3 多维列表
a = [1,2,3,4,5] # 一行五列multi_dim_a = [[1,2,3], [2,3,4], [3,4,5]] # 三行三列在上面定义的List中进行搜索:print(a[1])# 2print(multi_dim_a[0][1])# 2
11.4 dictionary 字典
模块
12.1 import 模块
12.2 自己的模块
其他
13.1 continue & break
13.2 try 错误处理
try:,except...as...:try: file=open('eeee.txt','r') #会报错的代码except Exception as e: # 将报错存储在 e 中 print(e)"""[Errno 2] No such file or directory: 'eeee.txt'""" 13.3 zip lambda map
a=[1,2,3]b=[4,5,6]ab=zip(a,b)print(list(ab)) #需要加list来可视化这个功能"""[(1, 4), (2, 5), (3, 6)]"""
lambda定义一个简单的函数,实现简化代码的功能


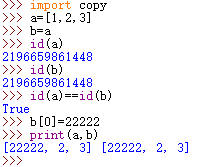
13.4 copy & deepcopy 浅复制 & 深复制